20 / 10 / 16
医学翻译学习-医学领域的机器学习
关于“医学领域的机器学习”一文医学翻译学习情况,记录于此。
一名49岁患者注意到自己肩部有一处无痛皮疹,但未就诊。几个月后,妻子让他去就诊,结果诊断出脂溢性角化病。之后,患者在接受结肠镜筛查时,护士注意到其肩部有一处深色斑疹,并建议其接受检查。1个月后,患者到皮肤科医师处就诊,医师采集了皮损活检标本。检查发现一处非癌性色素性皮损。皮肤科医师仍对皮损表示担心,因此要求对活检标本进行第二次读片,结果诊断出侵袭性黑色素瘤。肿瘤科医师对患者启动全身性化疗。患者的一位医师朋友问其为何未接受免疫治疗。
A 49-year-old patient notices a painless rash on his shoulder but does not seek care. Months later, his wife asks him to see a doctor, who diagnoses a seborrheic keratosis. Later, when the patient undergoes a screening colonoscopy, a nurse notices a dark macule on his shoulder and advises him to have it evaluated. One month later, the patient sees a dermatologist, who obtains a biopsy specimen of the lesion. The findings reveal a noncancerous pigmented lesion. Still concerned, the dermatologist requests a second reading of the biopsy specimen, and invasive melanoma is diagnosed. An oncologist initiates treatment with systemic chemotherapy. A physician friend asks the patient why he is not receiving immunotherapy.
笔记:
- painless rash 无痛皮疹
- seborrheic keratosis 脂溢性角化病
- screening colonoscopy 结肠镜筛查
- macule 斑疹
- systemic chemotherapy 全身性化疗
- immunotherapy 免疫治疗
- 用案例开启文章
如果每一项医疗决策(无论是重症监护医师还是社区卫生工作者做出的医疗决策)均由相关专家团队立即进行审核,并在决策看似有误的情况下提供指导,情况将会是什么样?新诊断出高血压,但无并发症的患者将接受已知最有效的药物,而非处方医师最熟悉的药物1,2 。开处方时无意中发生的过量和错误将很大程度上被消除3,4 。患神秘和罕见疾病的患者可被引导至其疑似诊断的相关领域知名专家处5 。
What if every medical decision, whether made by an intensivist or a community health worker, was instantly reviewed by a team of relevant experts who provided guidance if the decision seemed amiss? Patients with newly diagnosed, uncomplicated hypertension would receive the medications that are known to be most effective rather than the one that is most familiar to the prescriber.1,2 Inadvertent overdoses and errors in prescribing would be largely eliminated.3,4 Patients with mysterious and rare ailments could be directed to renowned experts in fields related to the suspected diagnosis.5
笔记:
- Inadvertent = unintentional
这样的系统看似难以实现。并无充足的医学专家可以参与其中,专家要花太长时间才能通读患者病史,而且与隐私法相关的顾虑也会导致工作尚未开始就已结束6 。然而,这正是医学领域机器学习展现的前景:几乎所有临床医师制订决策时蕴含的智慧以及数十亿患者的结局应该可以为每位患者的治疗提供指导。也就是说,每项诊断、管理决策和治疗都应结合集体的经验教训,从而根据患者的所有已知信息做到实时个体化。
Such a system seems far-fetched. There are not enough medical experts to staff it, it would take too long for experts to read through a patient’s history, and concerns related to privacy laws would stop efforts before they started.6 Yet, this is the promise of machine learning in medicine: the wisdom contained in the decisions made by nearly all clinicians and the outcomes of billions of patients should inform the care of each patient. That is, every diagnosis, management decision, and therapy should be personalized on the basis of all known information about a patient, in real time, incorporating lessons from a collective experience.
笔记:
- staff的用法值得注意
- inform的非常见用法:(formal) to have an influence on sth. 对…有影响
- That is VERSUS namely
- the wisdom contained in the decisions made by nearly all clinicians and the outcomes of billions of patients should inform the care of each patient 这句话其实可以抽出来做一个简单的长难句分析。其实这个句子逻辑性挺强的。主体结构A and B should influence on sth.;其中A结构里套俩过去分词,一层一层解开就行了;B同理。
这一框架强调机器学习不仅仅是像新药或新医疗器械一样的新工具,而是对超出人脑理解能力的数据进行有意义处理所需的基本技术;海量的信息储存日益见于庞大的临床数据库,甚至日益见于单一患者的数据7 。
This framing emphasizes that machine learning is not just a new tool, such as a new drug or medical device. Rather, it is the fundamental technology required to meaningfully process data that exceed the capacity of the human brain to comprehend; increasingly, this overwhelming store of information pertains to both vast clinical databases and even the data generated regarding a single patient.7
笔记:
- framing VERSUS structure
- pertain to GRE词汇了解一下
- 或许是语感的原因,“见于”或可替换为“涉及”
近50年前,本刊的一篇特别报告指出,计算功能将“增强医师的智力功能,并且在某些情况下很大程度上取代医师的智力功能8 。”然而,到了2019年初,机器学习在医疗领域发挥的推动作用仍然惊人地少。我们在本文中描述医学领域的机器学习要实现其全部前景,医疗系统必须做出的核心结构变化和模式转变(见视频),而非报告已经测试过的无数(关于回顾性数据的)概念验证模型
Nearly 50 years ago, a Special Article in the Journal stated that computing would be “augmenting and, in some cases, largely replacing the intellectual functions of the physician.”8 Yet, in early 2019, surprisingly little in health care is driven by machine learning. Rather than report the myriad proof-of-concept models (of retrospective data) that have been tested, here we describe the core structural changes and paradigm shifts in the health care system that are necessary to enable the full promise of machine learning in medicine (see video ).
什么是机器学习
Machine Learning Explained
传统上,软件工程师将知识经验浓缩提取成明确的计算机代码,而代码准确地指导计算机如何处理数据和做出决策。例如,如果患者血压升高且未接受抗高血压药治疗,则正确编程的计算机可提出治疗方案。这些基于规则的系统合乎逻辑并且可以解释,但是,正如本刊1987年一篇回音壁文章中所述,医学领域“如此广泛且复杂,即便并非不可能,也很难从规则中获取相关信息9 。”
Traditionally, software engineers have distilled knowledge in the form of explicit computer code that instructs computers exactly how to process data and how to make decisions. For example, if a patient has elevated blood pressure and is not receiving an antihypertensive medication, then a properly programmed computer can suggest treatment. These types of rules-based systems are logical and interpretable, but, as a Sounding Board article in the Journal in 1987 noted, the field of medicine is “so broad and complex that it is difficult, if not impossible, to capture the relevant information in rules.”9
笔记:
- 这一段整体比较简单。
传统方法和机器学习的关键区别是机器学习中的模型是从实例中学习,而不是用规则编程。对于给定的任务,实例是以输入(称为特征)和输出(称为标签)的形式提供。例如经病理科医师读片的数字化切片被转换成特征(切片的像素)和标签(例如表明切片包含癌变证据的信息)。计算机利用通过观察进行学习的算法,确定如何执行从特征到标签的映射,从而创建一个将信息泛化的模型,以便应用新的、以前从未见过的输入(例如未经人类读片的病理切片)来正确执行任务。这一过程称为监督学习,如图1所示。还有其他形式的机器学习10 。表1举例说明了在经同行评议的研究的基础上,输入-输出映射的临床实用性,或者现有机器学习能力经简单扩展后的临床实用性。
The key distinction between traditional approaches and machine learning is that in machine learning, a model learns from examples rather than being programmed with rules. For a given task, examples are provided in the form of inputs (called features) and outputs (called labels). For instance, digitized slides read by pathologists are converted to features (pixels of the slides) and labels (e.g., information indicating that a slide contains evidence of changes indicating cancer). Using algorithms for learning from observations, computers then determine how to perform the mapping from features to labels in order to create a model that will generalize the information such that a task can be performed correctly with new, never-seen-before inputs (e.g., pathology slides that have not yet been read by a human). This process, called supervised machine learning, is summarized in Figure 1 . There are other forms of machine learning.10 Table 1 lists examples of cases of the clinical usefulness of input-to-output mappings that are based on peer-reviewed research or simple extensions of existing machine-learning capabilities.
笔记:
- 生词不多,可以先看英文
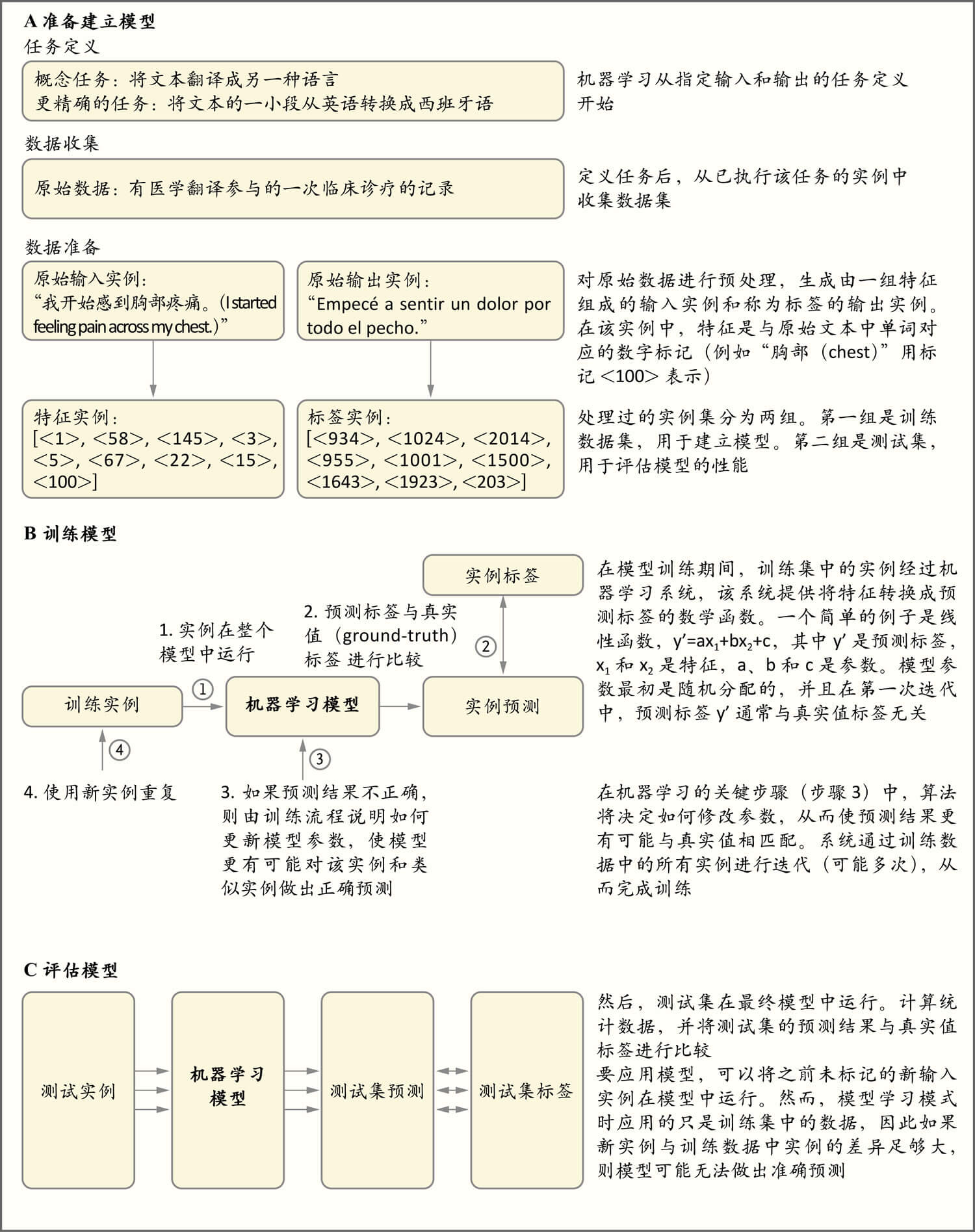
图1.监督学习的概念一览
Figure 1. Conceptual Overview of Supervised Machine Learning.
As shown in Panel A, machine learning starts with a task definition that specifies an input that should be mapped to a corresponding output. The task in this example is to take a snippet of text from one language (input) and produce text of the same meaning but in a different language (output). There is no simple set of rules to perform this mapping well; for example, simply translating each word without examining the context does not lead to high-quality translations. As shown in Panel B, there are key steps in training machine-learning models. As shown in Panel C, models are evaluated with data that were not used to build them (i.e., the test set). This evaluation generally precedes formal testing to determine whether the models are effective in live clinical environments involving trial designs.
如图A所示,机器学习从任务定义开始,任务定义说明了应映射到相应输出的输入。该实例的任务是从一种语言的文本(输入)中提取一小段,并生成具有相同含义但不同语言的文本(输出)。没有一套简单的规则可以很好地执行这种映射;例如简单地翻译每个单词而不考虑上下文并不能获得高质量的译文。如图B所示,训练机器学习模型有几个关键步骤。如图C所示,利用建立模型时未使用的数据(即测试集)来评估模型。此项评估一般在正式测试之前进行,旨在确定模型在试验设计(如随机临床试验)所涉及的现场临床环境中是否有效。
表1.驱动机器学习应用的输入和输出数据类型实例
Table 1. Examples of Types of Input and Output Data That Power Machine-Learning Applications.
笔记:
- power
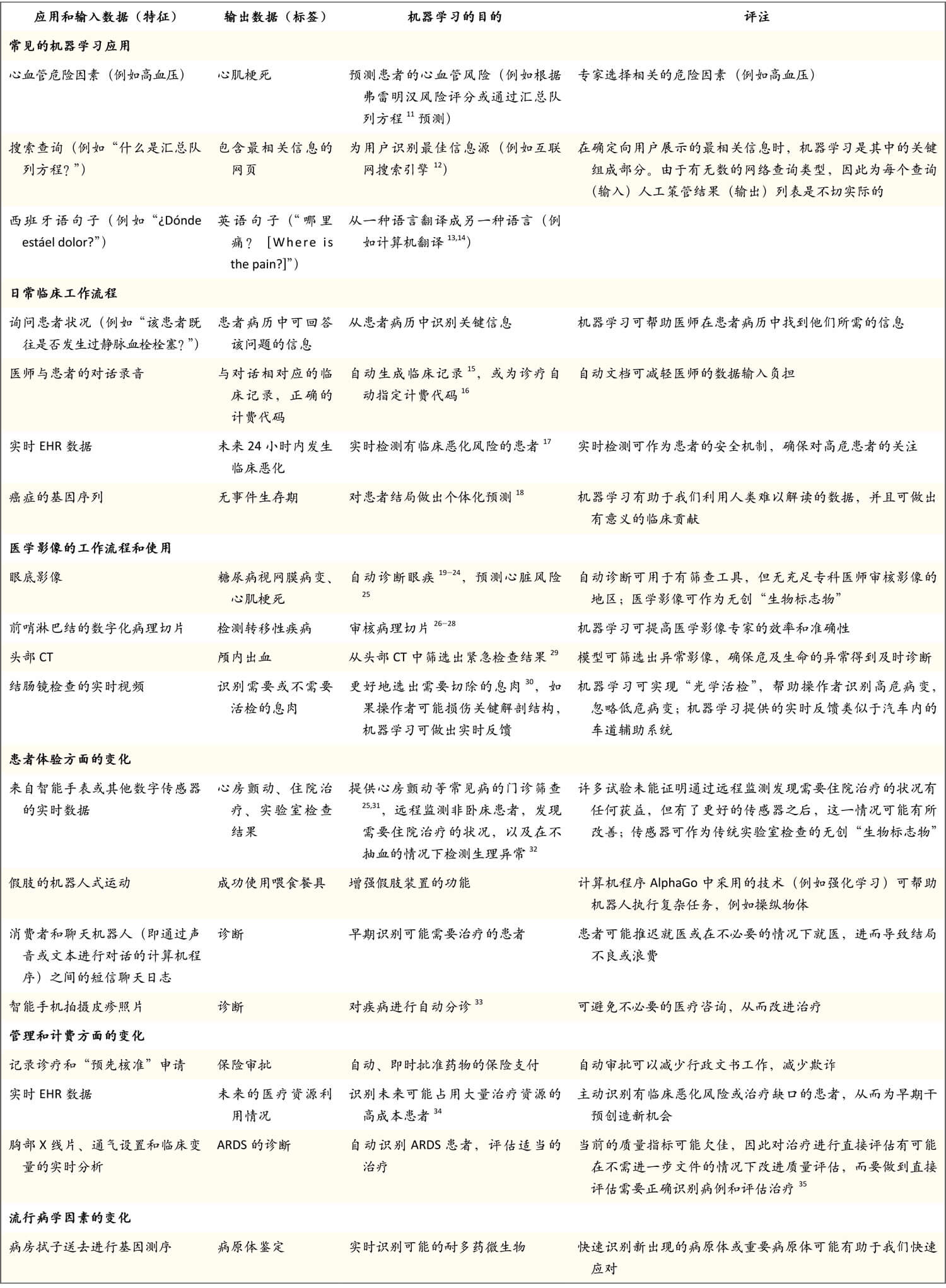
机器学习模型需要收集历史输入和输出数据,它们也称为特性和标签。例如一项确定基线心血管危险因素,然后对患者心肌梗死发生情况进行随访的研究将提供训练实例,其中特征是一组危险因素,标签是未来的心肌梗死。该模型经过训练之后,可根据特征预测标签,因此可预测新患者的标签发生风险。这一通用框架可用于多种任务。ARDS指的是急性呼吸窘迫综合征,CT指的是计算机断层扫描,EHR指的是电子病历。
Machine-learning models require collection of historical input and output data, which are also called features and labels. For example, a study that determined baseline cardiovascular risk factors and then followed patients for the occurrence of myocardial infarction would provide training examples in which the features were the set of risk factors and the label was a future myocardial infarction. The model would be trained to use the features to predict the label, so far new patients, the model would predict the risk of the occurrence of the label. This general framework can be used for a variety of tasks. ARDS denotes acute respiratory distress syndrome, CT computed tomography, and EHR electronic health record.
在预测的准确性至关重要的应用中,模型在数百万个特征和实例中发现统计学模式的能力是实现超人性能的关键。然而,发现这些模式之后,不一定可相应地识别出基础生物学通路或可改变的危险因素,而这些通路和危险因素才是开发新疗法的基础。
In applications in which predictive accuracy is critically important, the ability of a model to find statistical patterns across millions of features and examples is what enables superhuman performance. However, these patterns do not necessarily correspond to the identification of underlying biologic pathways or modifiable risk factors that underpins the development of new therapies.
笔记:
- 第一句翻译感觉有些拗口,其中in which的处理不是特别地道;superhuman直接处理成超人...好容易出戏啊。个人给的参考译文是:
- 在机器学习应用中,预测的准确性至关重要;因而应用内模型通过数百万个特征和实例获得统计学模式的能力才是应用展现非凡性能的关键。
机器学习模型和传统统计学模型之间没有清晰的界限,近期发表的一篇论文总结了两者之间的关系36 。然而,新的复杂机器学习模型(例如在“深度学习”中使用的模型,深度学习指的是利用人工神经网络的一类机器学习算法,该算法可学习特征和标签之间极其复杂的关系,并且已被证明对影像分类等任务的执行能力超过人类37,38 )非常适合利用现代临床治疗中获得的复杂且异质的数据类型(例如医师输入的医疗记录、医学影像、来自传感器的连续监测数据以及基因组数据),并从中进行学习,从而协助做出医学相关预测。表2指导我们何时使用简单的机器学习模型,何时使用复杂模型。
There is no bright line between machine-learning models and traditional statistical models, and a recent article summarizes the relationship between the two.36 However, sophisticated new machine-learning models (e.g., those used in “deep learning” [a class of machine-learning algorithms that use artificial neural networks that can learn extremely complex relationships between features and labels and have been shown to exceed human abilities in performing tasks such as classification of images]37,38 ) are well suited to learn from the complex and heterogeneous kinds of data that are generated from modern clinical care, such as medical notes entered by physicians, medical images, continuous monitoring data from sensors, and genomic data to help make medically relevant predictions. Guidance on when to use simple or sophisticated machine-learning models is provided in Table 2 .
笔记:
- there is no bright line between,这个句型很棒
表2. 决定需要哪类模型时要问的关键问题
人类学习和机器学习之间的一个关键区别是人类可以学会通过少量数据建立一般和复杂关联。例如一个蹒跚学步的孩子并不需要见过许多猫科动物实例就可以认出猎豹是猫科动物。一般而言,机器学习相同任务所需的实例数量远超过人类所需的实例数量,而且机器没有常识。然而,事情的另一面是,机器可以从大量数据中学习39 。使用电子病历(EHR)中存储的数千万患者病历(包含数千亿个数据点)训练机器学习模型是完全可行的,且过程中不会发生分心疏忽,而人类医师整个职业生涯中诊疗过的患者数量很难超过几万。
A key difference between human learning and machine learning is that humans can learn to make general and complex associations from small amounts of data. For example, a toddler does not need to see many examples of a cat to recognize a cheetah as a cat. Machines, in general, require many more examples than humans to learn the same task, and machines are not endowed with common sense. The flipside, however, is that machines can learn from massive amounts of data.39 It is perfectly feasible for a machine-learning model to be trained with the use of tens of millions of patient charts stored in electronic health records (EHRs), with hundreds of billions of data points, without any lapses of attention, whereas it is very difficult for a human physician to see more than a few tens of thousands of patients in an entire career.
笔记:
- 中文译文最后一句并不是特别好,或者说比较拗口。个人的一个参考版本是:
- 然而,对于人类医师个体而言,终其职业生涯,也很难接诊数万患者。
机器学习如何增进临床医师的工作
How Machine Learning Can Augment the Work of Clinicians
预后
PROGNOSIS
机器学习模型可以学习大量患者的健康轨迹模式。该设备可帮助医师站在专家的高度预测未来事件,获取信息的范围远超出个体医师的临床实践经验。例如患者重返工作岗位的可能性有多大,或者疾病进展速度将有多快?在人群水平,相同类型的预测能够可靠地识别很快将出现高危状况或所需医疗服务增多的患者;通过这些信息,我们可提供额外资源来主动支持上述患者40 。
A machine-learning model can learn the patterns of health trajectories of vast numbers of patients. This facility can help physicians to anticipate future events at an expert level, drawing from information well beyond the individual physician’s practice experience. For example, how likely is it that a patient will be able to return to work, or how quickly will the disease progress? At a population level, the same type of forecasting can enable reliable identification of patients who will soon have high-risk conditions or increased utilization of health care services; this information can be used to provide additional resources to proactively support them.40
笔记:
-
第二句的翻译似乎可以调整。
- 首先,facility处理为“设备”一词,似乎有些想当然了。从上下文看,取牛津词典第二个释义“a special feature of a machine, service, etc. that makes it possible to do sth extra (机器等的)特别装置;(服务等的)特色”,处理为“特点”之类的词或许更妥当。
- 原文:This facility can help physicians to anticipate future events at an expert level, drawing from information well beyond the individual physician’s practice experience.
- 原译:该设备可帮助医师站在专家的高度预测未来事件,获取信息的范围远超出个体医师的临床实践经验。
- 参考:该特点可帮助医师从专家高度预测未来事件,获取信远超个体医师实践经验的信息。
- 首先,facility处理为“设备”一词,似乎有些想当然了。从上下文看,取牛津词典第二个释义“a special feature of a machine, service, etc. that makes it possible to do sth extra (机器等的)特别装置;(服务等的)特色”,处理为“特点”之类的词或许更妥当。
-
人群水平 population level
-
support为啥一定要处理为“支持”?
大型综合医疗系统已经在使用简单的机器学习模型自动识别有可能被转入重症监护病房的住院患者17 ,此外回顾性研究提示,可以利用EHR41 和医学影像的原始数据建立更复杂和准确的预后模型42 。
Large integrated health systems have already used simple machine-learning models to automatically identify hospitalized patients who are at risk for transfer to the intensive care unit,17 and retrospective studies suggest that more complex and accurate prognostic models can be built with raw data from EHRs41 and medical imaging.42
笔记:
- 中文译本中的“此外”,感觉不够妥当,逻辑上非并列。
建立机器学习系统需要可说明患者综合纵向状况的数据,并利用这些数据进行训练。只有建立模型时使用的数据集中包含结局时,模型才能学习患者会发生什么情况。然而,数据目前被分别保存在EHR系统、医学影像存档和传输系统、支付方、药品福利主管(pharmacy benefits manager),甚至患者手机的应用程序中。一个解决方案是系统性地将数据放在患者自己手中。我们长期以来一直倡导这种解决方案43 ,患者控制的应用程序编程接口如今正被快速采纳,它使得上述解决方案得以实现44 。
Building machine-learning systems requires training with data that provide an integrated, longitudinal view of a patient. A model can learn what happens to patients only if the outcomes are included in the data set that the model is based on. However, data are currently siloed in EHR systems, medical imaging picture archiving and communication systems, payers, pharmacy benefits managers, and even apps on patients’ phones. A natural solution would be to systematically place data in the hands of patients themselves. We have long advocated for this solution,43 which is now enabled by the rapid adoption of patient-controlled application programming interfaces.44
笔记:
- silo的用法第一次见
- natural在中文译文中没有体现,最后一句中文译文似乎有些歧义
- 原文:A natural solution would be to systematically place data in the hands of patients themselves. We have long advocated for this solution,43 which is now enabled by the rapid adoption of patient-controlled application programming interfaces.[44](
- 原译:一个解决方案是系统性地将数据放在患者自己手中。我们长期以来一直倡导这种解决方案43 ,患者控制的应用程序编程接口如今正被快速采纳,它使得上述解决方案得以实现44 。
- 参考:常见的解决方案是让患者自己系统性地掌控数据,这也是我们一直倡导的方式。患者可控的应用程序编程接口(API)目前应用广泛,这使得上述解决方案得以实现。
统一数据格式(例如快速医疗互操作性资源[Fast Healthcare Interoperability Resources,FHIR])45 融合之后,我们将能够进行数据汇总。然后,患者可以决定允许哪些人访问其数据,进而用于建立或运行模型。有人担心技术互操作性不能解决EHR数据在语义标准化方面广泛存在的问题46 ,但通过HTML(超文本标记语言),我们已经为可能比EHR数据更混乱的网络数据建立索引,并且HTML已经在搜索引擎中发挥功用。
Convergence of a unified data format such as Fast Healthcare Interoperability Resources (FHIR)45 would allow for useful aggregation of data. Patients could then control who had access to their data for use in building or running models. Although there are concerns that technical interoperability does not solve the problem of semantic standardization endemic in EHR data,46 the adoption of HTML (Hypertext Markup Language) has allowed Web data, which are perhaps even messier than EHR data, to be indexed and made useful with search engines.
笔记:
- 最后一句,可以自己翻译着试试,基本算是长难句了吧
诊断
DIAGNOSIS
每个患者都是独特的,但最好的医师可以确定患者特有的细微体征属于正常值还是异常值。通过机器学习检测出的统计学模式可否帮助医师识别他们不经常诊断的疾病?
Every patient is unique, but the best doctors can determine when a subtle sign that is particular to a patient is within the normal range or indicates a true outlier. Can statistical patterns detected by machine learning be used to help physicians identify conditions that they do not diagnose routinely?
美国医学科学院(Institute of Medicine)的结论是,每个患者一生中几乎都会遇到诊断错误47 ,而正确诊断疾病对得到适当治疗至关重要48 。这一问题并不仅限于罕见疾病。心源性胸痛、结核、痢疾和分娩并发症在发展中国家经常被漏诊,即使是在治疗机会、检查时间和接受过充分培训的医务人员足够的情况下49 。
The Institute of Medicine concluded that a diagnostic error will occur in the care of nearly every patient in his or her lifetime,47 and receiving the right diagnosis is critical to receiving appropriate care.48 This problem is not limited to rare conditions. Cardiac chest pain, tuberculosis, dysentery, and complications of childbirth are commonly not detected in developing countries, even when there is adequate access to therapies, time to examine patients, and fully trained providers.49
笔记:
- 最后一句可否调换语序?
利用常规治疗中收集的数据,机器学习可以在临床诊疗中确定可能的诊断,并提高对临床表现出现时间较晚的疾病的关注50 。然而,这种方法有局限性。不太熟练的临床医师可能无法获得模型为其提供有意义协助所需的信息,并且建立模型时所依据的诊断可能是临时或不正确的诊断48 ,可能是未表现出症状的疾病(因此可能导致过度诊断)51 ,可能受计费的影响52 ,或者可能根本未被记录。然而,模型可以根据实时收集的数据向医师建议应提的问题或应做的检查53 ;这些建议在后果严重的误诊常见(如分娩)或临床医师不确定的情况下可能会有所帮助。临床正确诊断与EHR或索偿书中记录的诊断之间的差异意味着临床医师从一开始就应参与其中,确定常规治疗中产生的数据应如何应用于诊断过程的自动化。
With data collected during routine care, machine learning could be used to identify likely diagnoses during a clinical visit and raise awareness of conditions that are likely to manifest later.50 However, such approaches have limitations. Less skilled clinicians may not elicit the information necessary for a model to assist them meaningfully, and the diagnoses that the models are built from may be provisional or incorrect,48 may be conditions that do not manifest symptoms (and thus may lead to overdiagnosis),51 may be influenced by billing,52 or may simply not be recorded. However, models could suggest questions or tests to physicians53 on the basis of data collected in real time; these suggestions could be helpful in scenarios in which high-stakes misdiagnoses are common (e.g., childbirth) or when clinicians are uncertain. The discordance between diagnoses that are clinically correct and those recorded in EHRs or reimbursement claims means that clinicians should be involved from the outset in determining how data generated as part of routine care should be used to automate the diagnostic process.
模型已训练成功,可识别各类型影像中的异常。然而,对作为临床医师常规工作一部分的机器学习模型开展的前瞻性试验有限19,20 。
Models have already been successfully trained to retrospectively identify abnormalities across a variety of image types. However, only a limited number of prospective trials involve the use of machine-learning models as part of a clinician’s regular course of work.19,20
治疗
TREATMENT
在有数万医师治疗数千万名患者的大型医疗系统中,患者就诊的时间和原因,以及类似疾病患者的治疗方式存在差异。模型可否对这些天然差异进行分类,帮助医师确定集体经验何时提出更好的治疗方式?
In a large health care system with tens of thousands of physicians treating tens of millions of patients, there is variation in when and why patients present for care and how patients with similar conditions are treated. Can a model sort through these natural variations to help physicians identify when the collective experience points to a preferred treatment pathway?
一个简单的应用是将医师诊疗时开出的治疗方式与模型预测的治疗方式进行比较,并标注出差异供审核(例如其他临床医师大多开出符合新指南的另一种治疗方式)。然而,根据历史数据训练出的模型只是学习了医师的处方习惯,而不一定是规范的临床实践。如果希望模型学习哪些药物或治疗对患者最为有益,则需要仔细策管数据或估计因果效应,而机器学习模型并不一定能够识别因果效应,有时机器学习模型不能根据给定的数据识别因果效应。
A straightforward application is to compare what is prescribed at the point of care with what a model predicts would be prescribed, and discrepancies could be flagged for review (e.g., other clinicians tend to order an alternative treatment that reflects new guidelines). However, a model trained on historical data would learn only the prescribing habits of physicians, not necessarily the ideal practices. To learn which medication or therapy should be prescribed to maximize patient benefit requires either carefully curated data or estimates of causal effects, which machine-learning models do not necessarily — and sometimes cannot with a given data set — identify.
笔记:
- 最后一句感觉很冗长,给了一个参考译文,但不是特别满意。
- 原文:To learn which medication or therapy should be prescribed to maximize patient benefit requires either carefully curated data or estimates of causal effects, which machine-learning models do not necessarily — and sometimes cannot with a given data set — identify.
- 原译:如果希望模型学习哪些药物或治疗对患者最为有益,则需要仔细策管数据或估计因果效应,而机器学习模型并不一定能够识别因果效应,有时机器学习模型不能根据给定的数据识别因果效应。
- 参考:如果希望模型学习哪些药物或治疗对患者最为有益,则需要仔细策管数据或估计因果效应,而后者不一定能够为机器学习模型所识别(有时给定数据集亦无法识别)。
疗效比较研究和实用性试验54 中使用的传统方法提供了来自观察数据的重要启示55 。然而,最近使用机器学习所做的尝试表明,要做到以下几点有一定的挑战:与专家一起生成策管的数据集、更新模型以便纳入新发布的证据、对其进行调整以便适合各地区的处方习惯以及从EHR中自动提取相关变量以便使用56 。
Traditional methods used in comparative effectiveness research and pragmatic trials54 have provided important insights from observational data.55 However, recent attempts at using machine learning have shown that it is challenging to generate curated data sets with experts, update the models to incorporate newly published evidence, tailor them to regional prescribing practices, and automatically extract relevant variables from EHRs for ease of use.56
机器学习还可根据临床文件自动选择可能符合随机对照试验纳入标准的患者57 ,或识别可能在研究中受益于早期疗法或新疗法的高危患者或患者亚群。通过上述努力,医疗系统能够以更低的成本和管理费用对符合临床均势的各种临床场景进行更严格的研究54,58,59 。
Machine learning can also be used to automatically select patients who might be eligible for randomized, controlled trials on the basis of clinical documentation57 or to identify high-risk patients or subpopulations who are likely to benefit from early or new therapies under study. Such efforts can empower health systems to subject every clinical scenario for which there is equipoise to more rigorous study with decreased cost and administrative overhead.54,58,59
笔记:
- clinical equipoise Clinical equipoise, also known as the principle of equipoise, provides the ethical basis for medical research that involves assigning patients to different treatment arms of a clinical trial. The term was first used by Benjamin Freedman in 1987. 均势可定义为“平衡”或“均等分配”。在临床试验中,“临床均势”涉及到任一干预疗法效果的不确定性,即,不确定例如两种研究治疗组其中之一的任一干预疗法是否能提供比另外一种疗法更好的效果。根据均势原则,只有在确实无法确定哪种干预疗法才能对受试者更加有利的情况下,才会让他们随机选择要参加的对照试验。
临床医师工作流程
CLINICIAN WORKFLOW
EHR的引入提高了数据的利用度。然而,这些系统也让临床医师感到挫败,原因是系统中一大堆关于计费或管理的复选框60 、笨拙的用户界面61,62 、输入数据所需的时间增加63-66 以及发生医疗错误的新的可能性67 。
The introduction of EHRs has improved the availability of data. However, these systems have also frustrated clinicians with a panoply of checkboxes for billing or administrative documentation,60 clunky user interfaces,61,62 increased time spent entering data,63-66 and new opportunities for medical errors.67
许多消费产品中使用的机器学习技术也可用于提高临床医师的效率。搜索引擎中使用的机器学习可为临床医师提供帮助,使其无须多次点击即可显示患者病历中的相关信息。预测键入、语音听写和自动摘要等机器学习技术可改进表单和文本字段的数据输入。预先核准可以由模型代替,这些模型根据患者病历中的信息自动核准支付68 。运用这些能力不仅仅是为了方便医师。临床数据的顺利查看和输入是数据收集和记录的基本前提,而数据收集和记录又使机器学习能够为每位患者提出尽可能好的治疗。最重要的是,效率的提高、文档的简化和自动化临床工作流程的改进将使临床医师有更多的时间与患者在一起。
The same machine-learning techniques that are used in many consumer products can be used to make clinicians more efficient. Machine learning that drives search engines can help expose relevant information in a patient’s chart for a clinician without multiple clicks. Data entry of forms and text fields can be improved with the use of machine-learning techniques such as predictive typing, voice dictation, and automatic summarization. Prior authorization could be replaced by models that automatically authorize payment based on information already recorded in the patient’s chart.68 The motivation behind adopting these abilities is not just convenience to physicians. Making the process of viewing and entering the most clinically useful data frictionless is essential to capturing and recording health care data, which in turn will enable machine learning to help give the best possible care to every patient. Most importantly, increased efficiency, ease of documentation, and improved automated clinical workflow would allow clinicians to spend more time with their patients.
笔记:
- 专业文献的翻译似乎理应规避掉口语化现象,比如中文译文中的“在一起”。
在EHR系统之外,机器学习技术还适用于外科视频的实时分析,从而帮助外科医师避开关键解剖结构或意外变异,机器学习技术甚至可以处理比较单调的任务,例如准确计数手术敷料。核对清单有助于避免手术错误69 ,而对其执行情况的无间断自动监测进一步提高了安全性。
Even outside the EHR system, machine-learning techniques can be adapted for real-time analysis of video of the surgical field to help surgeons avoid critical anatomical structures or unexpected variants or even handle more mundane tasks such as accurate counting of surgical sponges. Checklists can prevent surgical error,69 and unstinting automated monitoring of their implementation provides additional safety.
笔记:
- 中文加粗处的处理很有意思(拆句)
临床医师生活中可能也在智能手机上使用这些技术的变体。尽管已经有回顾性概念验证研究评估了这些技术在医学领域的应用15 ,但这些技术要得到采纳,遇到的主要障碍不是在模型开发方面,而是在以下方面:技术的基础设施,EHR的法律、隐私和政策框架,卫生系统,以及技术提供商。
In their personal lives, clinicians probably use variants of all these forms of technology on their smartphones. Although there are retrospective proof-of-concept studies of application of these techniques to medical contexts,15 the major barriers to adoption involve not the development of models but technical infrastructure; legal, privacy, and policy frameworks across EHRs; health systems; and technology providers.
扩大临床专业技能的可及性
EXPANDING THE AVAILABILITY OF CLINICAL EXPERTISE
医师不可能与需要治疗的所有患者逐一交流。机器学习能否扩大临床医师可及的范围,从而在无须临床医师亲自参与的情况下提供专家级的医疗评估?例如新发皮疹的患者可以发送智能手机拍摄的照片,然后得到诊断32,33 ,从而避免不必要的急诊就诊。考虑去急诊就诊的患者可以与自动分诊系统沟通,分诊系统在适合的情况下引导其接受其他形式的治疗。患者确实需要专业人员帮助时,模型可以确定具有相关专业技能并且有时间接诊的医师。同样,为了提高舒适度和降低成本,如果机器可以远程监测传感器数据,则原本可能需要住院的患者可以待在家中接受治疗。
There is no way for physicians to individually interact with all the patients who may need care. Can machine learning extend the reach of clinicians to provide expert-level medical assessment without personal involvement? For example, patients with new rashes may be able to obtain a diagnosis by sending a picture that they take on their smartphones,32,33 thereby averting unnecessary urgent-care visits. A patient considering a visit to the emergency department might be able to converse with an automated triage system and, when appropriate, be directed to another form of care. When a patient does need professional assistance, models could identify physicians with the most relevant expertise and availability. Similarly, to increase comfort and lower cost, patients who otherwise may need to be hospitalized could stay at home if machines can remotely monitor their sensor data.
如果某些地区的患者获得医疗专业人员直接协助的途径有限70 且过程复杂,那么将机器学习系统做出的判断直接发送给患者具有重要意义。即使在专业临床医师充足的地区,这些临床医师也担心自己的能力和努力程度无法及时、准确解读患者身上的传感器或运动追踪设备所收集的海量数字式数据71 。事实上,通过数百万患者就诊数据训练出的机器学习模型有望帮助医疗专业人员具备更好的决策能力。例如护士可承担许多传统上由医师执行的任务,初级保健医师可履行一些传统上由专科医师承担的角色,专科医师可将更多的时间用于可从其专业技能受益的患者。
The delivery of insights from machine learning directly to patients has become increasingly important in the areas of the world where access to direct medical expertise is in limited supply70 and sophistication. Even in areas where the supply of expert clinicians is abundant, these clinicians are concerned about their ability and the effort required to provide timely and accurate interpretation of the tsunami of patient-driven digital data from sensor or activity-tracking devices worn by patients.71 Indeed, one of the hopes with regard to machine-learning models trained with data from millions of patient encounters is that they can equip health care professionals with the ability to make better decisions. For instance, nurses might be able to take on many tasks that are traditionally performed by doctors, primary care doctors might be able to perform some of the roles traditionally performed by medical specialists, and medical specialists could devote more of their time to patients who would benefit from their particular expertise.
笔记:
- 第一句想不通为什么要加“如果”,有点画蛇添足
- 最后一句似乎也有语病(亦或是我中文太差),“履行”何以搭配“角色”?“担当”之类的如何?
不涉及机器学习的各种手机应用程序或网络服务已被证明可提高用药依从性72 和慢性病控制效果73,74 。然而,在直接面向患者的应用中,机器学习遇到的障碍是缺少正式的回顾性和前瞻性评估方法75 。
A variety of mobile apps or Web services that do not involve machine learning have been shown to improve medication adherence72 and control of chronic diseases.73,74 However, machine learning in direct-to-patient applications is hindered by formal retrospective and prospective evaluation methods.75
笔记:
- 第一句的“被”字,似乎可以调整
主要挑战
Key Challenges
高质量数据的利用度
AVAILABILITY OF HIGH-QUALITY DATA
在建立机器学习模型的过程中,核心挑战是收集到具有代表性的多样化数据集。理想做法是确定模型使用中预期将会遇到的数据格式和质量,然后利用与之最相似的数据来训练模型。例如,对于计划在床旁使用的模型,最好应用EHR中相应时刻的相同数据,即使已知这些数据不可靠46 或存在不需要的变异性46,76 。足够大的数据集可以成功地训练现代模型,从而将有噪输入映射到有噪输出。使用较小规模的策管数据集(例如临床试验中通过人工病历审核收集的数据)并非理想做法,除非床旁临床医师将根据最初的试验规范手动提取变量。这种做法对于某些变量可能可行,但对于做出最准确预测所需的数十万EHR变量并不可行41 。
A central challenge in building a machine-learning model is assembling a representative, diverse data set. It is ideal to train a model with data that most closely resemble the exact format and quality of data expected during use. For instance, for a model that is intended to be used at the point of care, it is preferable to use the same data that are available in the EHR at that particular moment, even if they are known to be unreliable46 or subject to unwanted variability.46,76 When they have large enough data sets, modern models can be successfully trained to map noisy inputs to noisy outputs. The use of a smaller set of curated data, such as those collected in clinical trials from manual chart review, is suboptimal unless clinicians at the bedside are expected to abstract the variables by hand according to the original trial specifications. This practice might be feasible with some variables, but not with the hundreds of thousands that are available in the EHR and that are necessary to make the most accurate predictions.41
数据领域有一句格言是“垃圾进,垃圾出”,而我们又在使用有噪数据集训练模型,两者之间如何协调?如果希望了解复杂的统计学模式,最好有大规模数据集(即使是有噪数据集),但如果希望微调或评估模型,则必须有带策管标签的较小规模实例集。这样可以在原始标签可能有误的情况下,对照预期标签正确评估模型的预测结果21 。影像学模型通常需要多名评定人裁定每张影像,然后生成“真实值”(即无误的专家为某一实例指定的诊断或发现)标签,但对于非影像学任务,事后获得真实值也许是无法做到的,原因例如未获得必要的诊断性检查结果。
How do we reconcile the use of noisy data sets to train a model with the data maxim “garbage in, garbage out”? Although to learn the majority of complex statistical patterns it is generally better to have large — even noisy — data sets, to fine-tune or evaluate a model, it is necessary to have a smaller set of examples with curated labels. This allows for proper assessment of the predictions of a model against the intended labels when there is a chance that the original ones were mislabeled.21 For imaging models, this generally requires generating a “ground truth” (i.e., diagnoses or findings that would be assigned to an example by an infallible expert) label adjudicated by multiple graders for each image, but for nonimaging tasks, obtaining ground truth may be impossible after the fact if, for example, a necessary diagnostic test was not obtained.
机器学习模型一般在有大量训练数据的情况下表现最佳。因此,在机器学习的许多用途中,一个关键问题平衡以下两方面,一方面是隐私和法规,另一方面是希望利用大量的多样化数据集来提高机器学习模型的准确性。
Machine-learning models generally perform best when they have access to large amounts of training data. Thus, a key issue for many uses of machine learning will be balancing privacy and regulatory requirements with the desire to leverage large and diverse data sets to improve the accuracy of machine-learning models.
笔记:
- 后半句英文的逻辑结构很值得学习,中文则似乎需要优化。(“一个关键问题平衡”这就有点太跟随原文了,调整成“关键在于”,似乎更好些)
- balance with 常见搭配
从过去的不可取做法中学习
LEARNING FROM UNDESIRABLE PAST PRACTICES
所有人类活动都存在不想要且无意识的偏差。机器学习系统的建立者和使用者需要仔细思考偏差如何影响用于训练模型77 的数据,并采用措施解决和监测这些偏差78 。
All human activity is marred by unwanted and unconscious bias. Builders and users of machine-learning systems need to carefully consider how biases affect the data being used to train a model77 and adopt practices to address and monitor them.78
机器学习的优势,也是其弱点之一是模型可以在历史数据中识别出人类无法发现的模式。来自医疗实践的历史数据显示出医疗差距,即为弱势群体提供的医疗系统性地劣于为其他人群提供的医疗77,79 。在美国,历史数据反映出对可能不必要的治疗和服务做出奖励的支付系统,而且历史数据中可能缺少应接受治疗,但实际未接受治疗的患者(例如无保险的患者)数据。
The strength of machine learning, but also one of its vulnerabilities, is the ability of models to discern patterns in historical data that humans cannot find. Historical data from medical practice indicate health care disparities in the provision of systematically worse care for vulnerable groups than for others.77,79 In the United States, the historical data reflect a payment system that rewards the use of potentially unnecessary care and services and may be missing data about patients who should have received care but did not (e.g., uninsured patients).
笔记:
第一句似乎“是”字前后顺序对调,更流畅一些。“可以在历史数据中识别出人类无法发现的模式,这既是机器学习的优势,也是其弱点之一。”
法规、监督和安全应用方面的专业技能
EXPERTISE IN REGULATION, OVERSIGHT, AND SAFE USE
卫生系统已经开发出确保向患者安全提供药物的复杂机制。机器学习的广泛应用也需要类似的复杂监管结构80 、法律框架81 和本地规范82 ,从而确保系统的安全开发、应用和监测。此外,技术公司必须提供可扩展的计算平台,用于处理大量数据和使用模型;然而,如今它们承担的角色尚不明确。
Health systems have developed sophisticated mechanisms to ensure the safe delivery of pharmaceutical agents to patients. The wide applicability of machine learning will require a similarly sophisticated structure of regulatory oversight,80 legal frameworks,81 and local practices82 to ensure the safe development, use, and monitoring of systems. Moreover, technology companies will have to provide scalable computing platforms to handle large amounts of data and use of models; their role today, however, is unclear.
至关重要的是,使用机器学习系统的临床医师和患者需要理解它们的局限性,包括在某些情况下,模型不能外推到特定场景83-85 。在决策或分析影像时过度依赖机器学习模型可能会导致自动化偏差86 ,医师对错误的警觉性可能降低。如果模型本身的可解释程度不够高,进而导致临床医师无法识别模型给出错误建议的情况,那么上述问题就尤其严重87,88 。在模型预测结果中给出置信区间可能有一定帮助,但置信区间本身也有可能被错误解读89,90 。因此,需要对正在使用的模型进行前瞻性的真实世界临床评估,而不仅仅是基于历史数据集进行回顾性的性能评估。
Critically, clinicians and patients who use machine-learning systems need to understand their limitations, including instances in which a model is not designed to generalize to a particular scenario.83-85 Overreliance on machine-learning models in making decisions or analyzing images may lead to automation bias,86 and physicians may have decreased vigilance for errors. This is especially problematic if models themselves are not interpretable enough for clinicians to identify situations in which a model is giving incorrect advice.87,88 Presenting the confidence interval in a prediction of a model may help, but confidence intervals themselves may be interpreted incorrectly.89,90 Thus, there is a need for prospective, real-world clinical evaluation of models in use rather than only retrospective assessment of performance based on historical data sets.
直接面向患者的机器学习应用需要有一些特别的考虑。患者可能无法验证模型制造商宣称的内容是否有高质量临床证据证实,也无法验证其建议的做法是否合理。
Special consideration is needed for machine-learning applications targeted directly to patients. Patients may not have ways to verify that the claims made by a model maker have been substantiated by high-quality clinical evidence or that a suggested action is reasonable.
笔记:
- “需要有一些特别的考虑”,似乎可以简化,“需单独考量”。
- 第二句前面加一个“因为”,似乎更好。
研究的发表和传播
PUBLICATIONS AND DISSEMINATION OF RESEARCH
建立模型的跨学科团队可能采用临床医师并不熟悉的途径发布结果。论文通常在arXiv和bioRxiv等预印服务网站在线发布91,92 ,并且许多模型的源代码保存在GitHub等存储库中。此外,经同行评议的许多计算机科学论文并非由传统期刊发表,而是作为会议论文集发表,例如神经信息处理系统大会(Neural Information Processing Systems,NeurIPS)和国际机器学习大会(International Conference on Machine Learning,ICML)的论文集。
The interdisciplinary teams that build models may report results in venues that may be unfamiliar to clinicians. Manuscripts are often posted online at preprint services such as arXiv and bioRxiv,91,92 and the source code of many models exists in repositories such as GitHub. Moreover, many peer-reviewed computer science manuscripts are not published by traditional journals but as proceedings in conferences such as the Conference on Neural Information Processing Systems (NeurIPS) and the International Conference on Machine Learning (ICML).
笔记:
- 根据2019年2月20日更新的github官网中文翻译中的词汇表,repository应处理为“仓库”[100]
- proceeding versus Conference Paper
结论
Conclusions
大量医疗数据的加速产生将从根本上改变医疗的性质。我们坚信,医患关系是为患者提供治疗的基石,通过机器学习做出的判断将丰富这一关系。我们预计,未来几年将会出现一些早期模型以及经同行评议的研究结果论文,同时监管框架和价值医疗(value-based care)的经济激励机制将有所发展,这些是我们对医学领域的机器学习持谨慎乐观态度的原因。我们对下面这个但愿不太遥远的未来充满期待:数百万临床医师为数十亿患者做出治疗决策时使用的所有医学相关数据由机器学习模型进行分析,从而帮助临床医师向所有患者提供可能的最佳治疗。
The accelerating creation of vast amounts of health care data will fundamentally change the nature of medical care. We firmly believe that the patient–doctor relationship will be the cornerstone of the delivery of care to many patients and that the relationship will be enriched by additional insights from machine learning. We expect a handful of early models and peer-reviewed publications of their results to appear in the next few years, which — along with the development of regulatory frameworks and economic incentives for value-based care — are reasons to be cautiously optimistic about machine learning in health care. We look forward to the hopefully not-too-distant future when all medically relevant data used by millions of clinicians to make decisions in caring for billions of patients are analyzed by machine-learning models to assist with the delivery of the best possible care to all patients.
一名49岁患者使用智能手机应用程序给肩部皮疹拍了一张照片,应用程序建议患者立即与皮肤科医师预约就诊时间。保险公司自动批准直接转诊,应用程序与附近一位有经验的皮肤科医师预约一个2日内的就诊时间。预约的就诊时间自动与患者的个人日历进行核对。皮肤科医师对皮损进行活检,病理科医师对Ⅰ期黑色素瘤这一计算机辅助诊断结果进行审核,然后由皮肤科医师将其切除。
A 49-year-old patient takes a picture of a rash on his shoulder with a smartphone app that recommends an immediate appointment with a dermatologist. His insurance company automatically approves the direct referral, and the app schedules an appointment with an experienced nearby dermatologist in 2 days. This appointment is automatically cross-checked with the patient’s personal calendar. The dermatologist performs a biopsy of the lesion, and a pathologist reviews the computer-assisted diagnosis of stage I melanoma, which is then excised by the dermatologist.